Abstract
DiLoCo is a powerful framework for training large language models (LLMs), enabling larger optimal batch sizes and increased accelerator utilization under networking constraints. However, DiLoCo's performance has been shown to degrade as the number of workers (K) increases. In this work, we posit that a related but often overlooked factor in DiLoCo's behavior is the choice of inner optimizer, which shapes the pseudogradient used by the outer optimizer. Given the recent success of Muon relative to AdamW for data parallel (DP) training, we examine how Muon's normalized optimizer steps can affect the pseudogradient's quality.
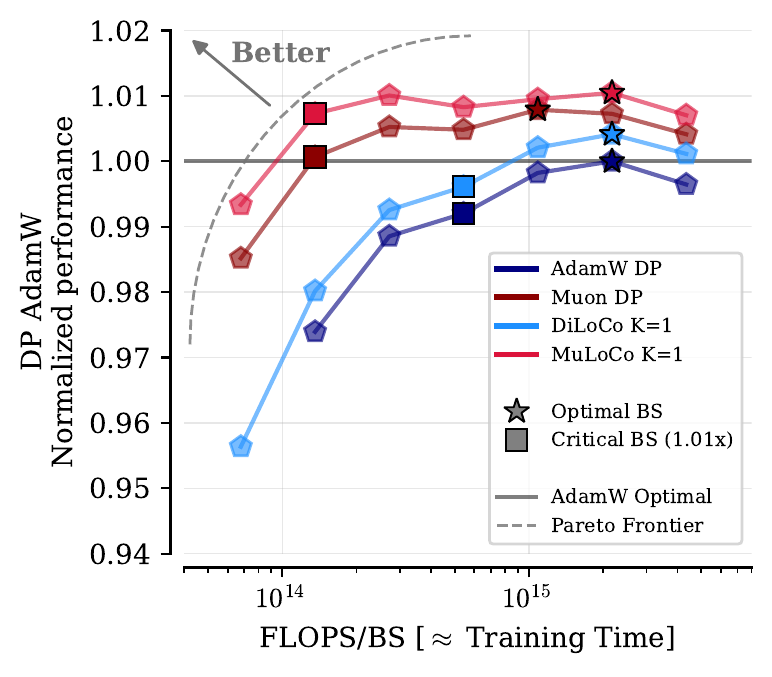
We find that, relative to AdamW, Muon yields more directionally correct pseudogradients as the number of workers (K) increases. In our experiments pre-training language models, we conduct extensive hyperparameter tuning across 150M, 416M, 914M, 1.76B, and 3.1B models for DiLoCo, MuLoCo, AdamW DP, and Muon DP. Consistently across all scales, we find that with K≥1 workers, MuLoCo (Muon inner optimizer DiLoCo) achieves superior performance to DiLoCo in absolute terms and for K>2 it outperforms DiLoCo relative to their data parallel baselines, while being compatible with quantization, streaming, and long synchronization intervals.
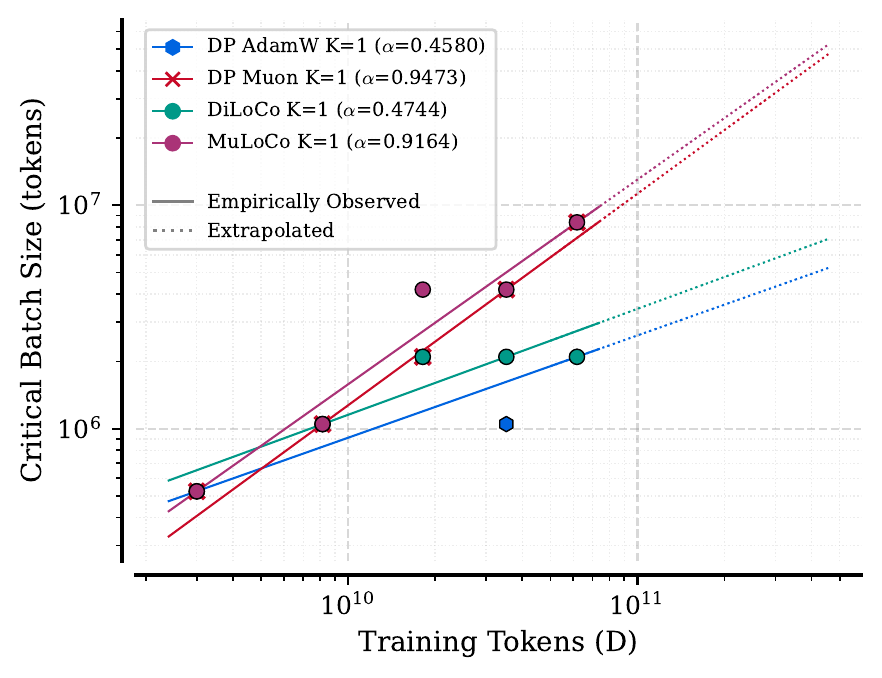
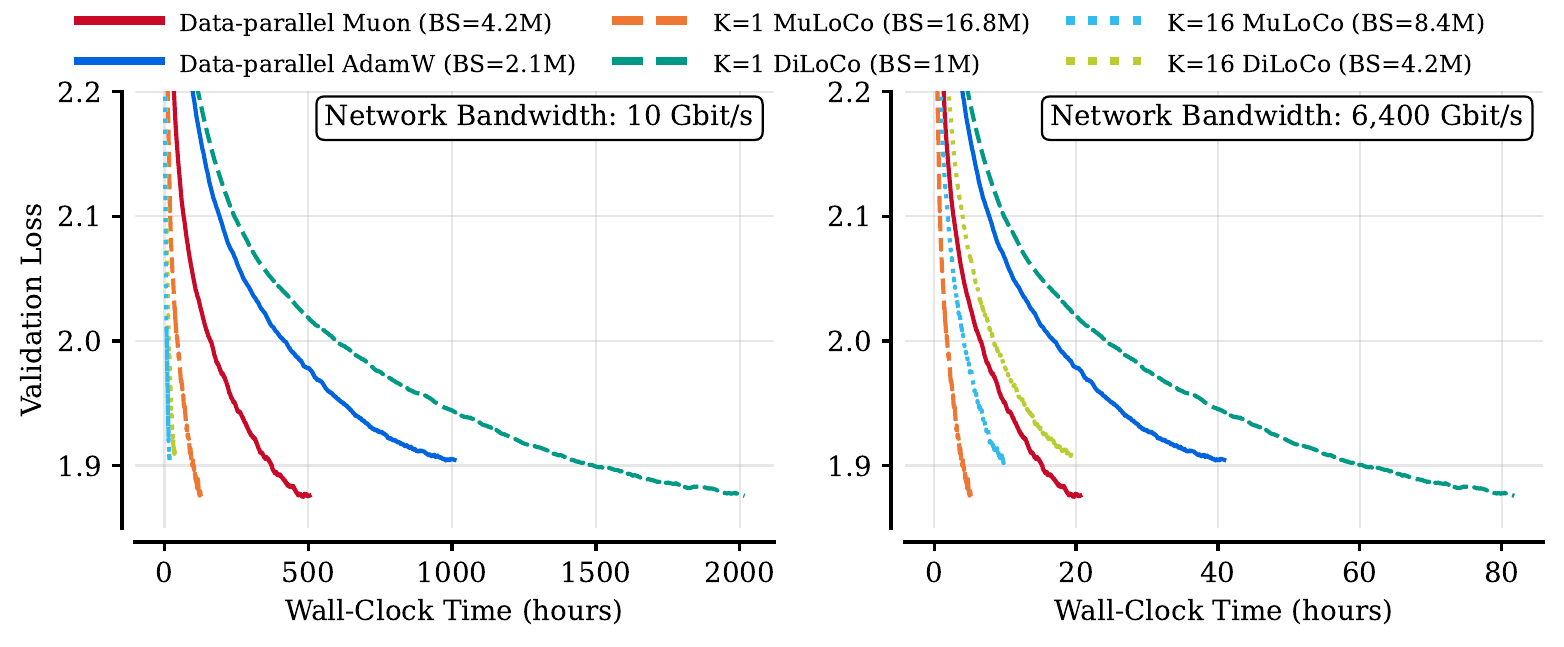
At K=1, we find that MuLoCo can even outperform the data-parallel gold standard while having larger critical batch sizes. Finally, we extrapolate optimal hyperparameters to 15B scale and train a model with each method (six in total) using K=1 and K=16 workers. We find that K=16 MuLoCo nearly matches single-worker performance at this scale, while MuLoCo K=1 matches the best performing baseline while using a much larger 16M token batch size.